Da Framablog ho ripreso e tradotto l’articolo di Stephane Bortzmeyer C’est quoi, l’interopérabilité, et pourquoi est-ce beau et bien.
Visto che era un riferimento importante per la comprensione dell’articolo, ho tradotto anche l’appello per l’interoperabilità dei giganti del web, lanciato da La Qudrature du Net e da altre associazioni.
Buona lettura 🙂
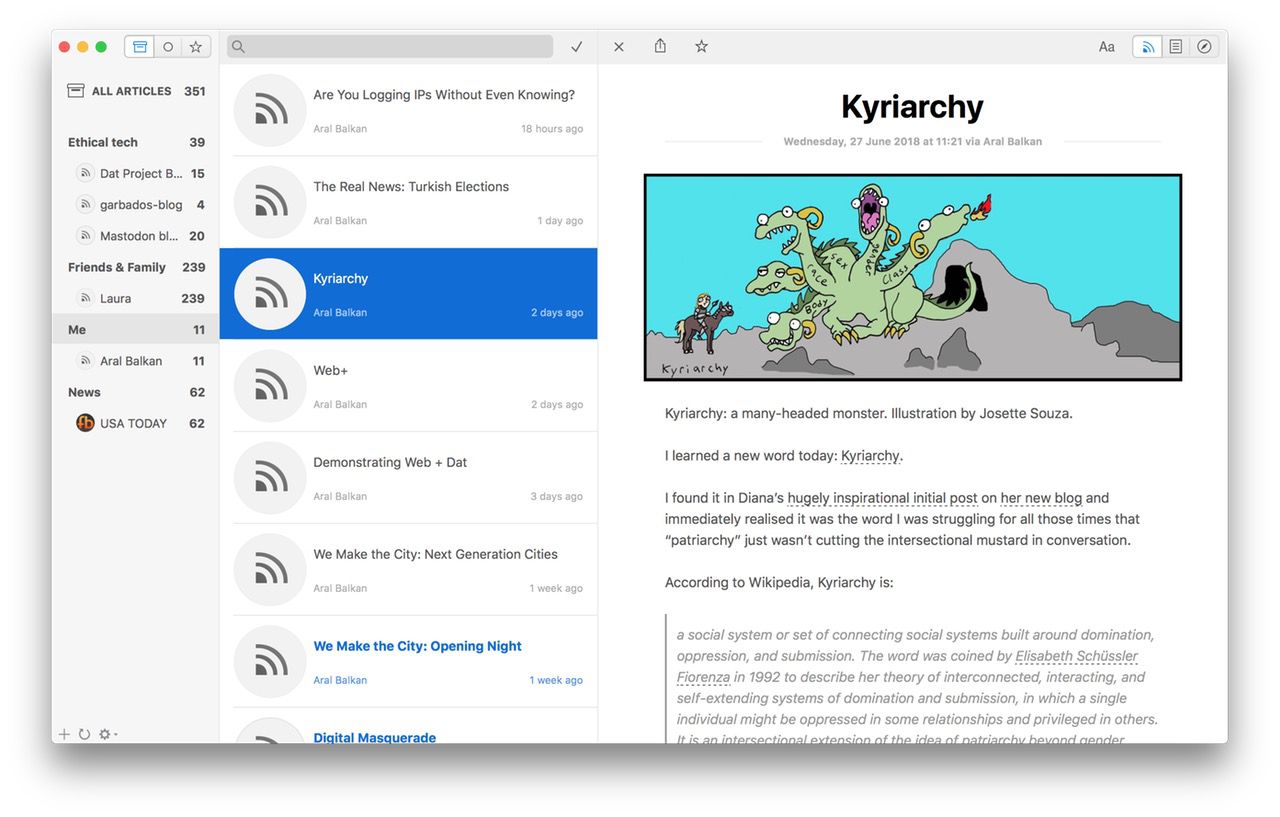
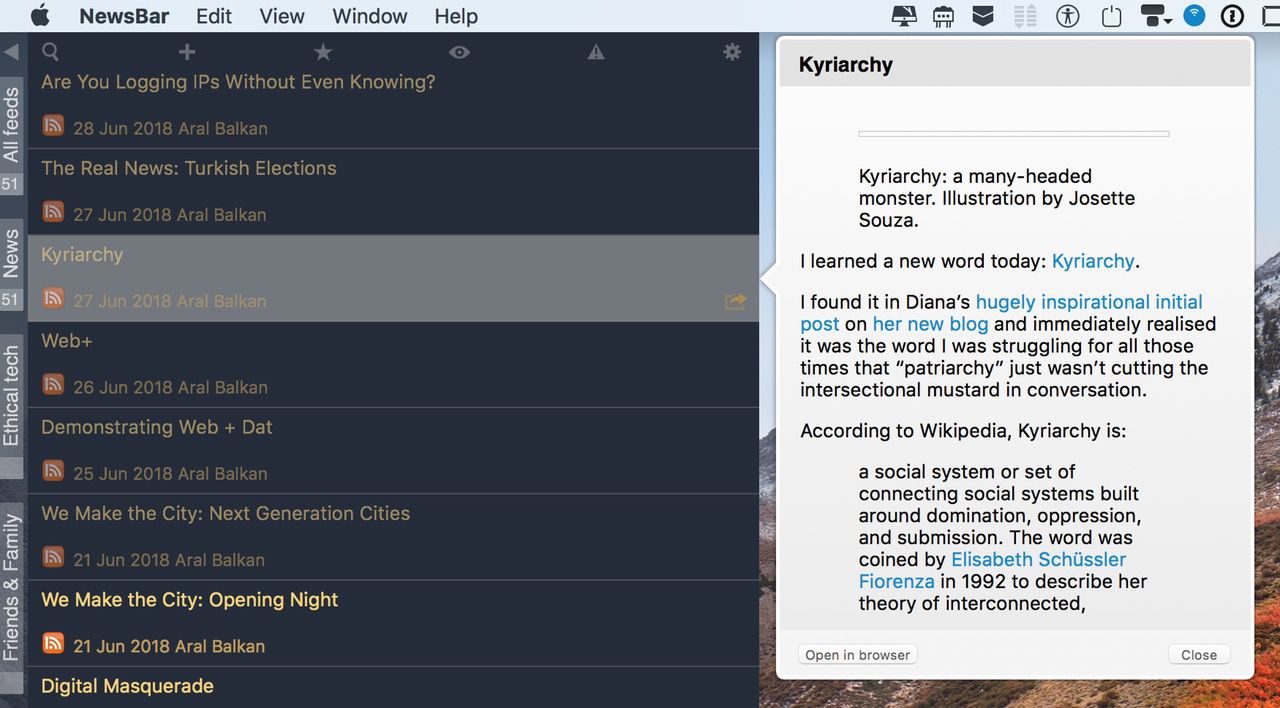
Protocollo, HTTP, interoperabilità, questi termini ti dicono qualcosa? E standard, specifiche, RFC, tutto chiaro?
Se hai bisogno di capire un po’ meglio, l’articolo qui sotto è un pezzo scelto, scritto da Stéphane Bortzmeyer che si è sforzato di rendere accessibili queste nozioni fondamentali.
Protocolli
Il 21 maggio 2019, sessantanove organizzazioni, tra cui Framasoft, hanno firmato un appello per l’imposizione, possibilmente per legge, di un minimo di interoperabilità per i grandi attori commerciali del Web.
“Interoperabilità” è una bella parola, ma non è necessariamente parte del vocabolario di tutti, e quindi merita di essere spiegata. Perciò parleremo di interoperabilità, di protocolli, di interfacce, di standard e spero di riuscire a farlo restando comprensibile (se sei uno specialista di informatica, tutto questo lo sai già, ma l’appello delle 69 organizzazioni riguarda tutti).
Il Web, o meglio tutta Internet, si basa su protocolli di comunicazione. Un protocollo è un insieme di regole che devono essere seguite se si desidera comunicare. Il termine deriva dalla comunicazione umana, ad esempio, quando incontriamo qualcuno, ci stringiamo la mano o ci presentiamo se l’altro non ci conosce, ecc. Negli umani, il protocollo non è rigido (tranne nel caso del ricevimento nel suo palazzo da parte della Regina d’Inghilterra, ma questo deve essere un fatto raro tra le lettrici e i lettori di Framablog). Se la persona con cui comunichi non rispetta esattamente il protocollo, la comunicazione può ancora avvenire, anche se ciò significa che questa persona è poco educata. Ma i software non funzionano come gli umani. A differenza degli umani, non hanno flessibilità, le regole devono essere seguite esattamente. Su una rete come Internet, perché due software possano comunicare, ognuno deve seguire esattamente le stesse regole, ed è l’insieme di queste regole che crea un protocollo.
Un esempio concreto? Sul Web, per consentire al browser di visualizzare la pagina desiderata, è necessario chiedere a un server Web uno o più file. La richiesta viene effettuata inviando al server la parola GET (“dammi” in inglese) seguita dal nome del file, seguito dalla parola “HTTP / 1.1”. Se un browser cercasse di inviare il nome del file prima della parola GET, il server non capirebbe niente e risponderebbe invece con un messaggio di errore. A proposito di errori, potresti aver già incontrato il numero 404 che è semplicemente il codice di errore usato dai software che parlano HTTP per indicare che la pagina richiesta non esiste. Questi codici numerici, progettati per essere utilizzati tra software, hanno il vantaggio sui testi di non essere ambigui e di non dipendere da un particolare linguaggio umano. Questo esempio descrive una parte molto piccola del protocollo denominato HTTP (sta per Hypertext Transfer Protocol ) che è il più utilizzato sul web.
Esistono protocolli molto più complessi. Il punto importante è che dietro lo schermo, i software comunicano tra loro utilizzando questi protocolli. Alcuni servono direttamente ai software che utilizzi (come HTTP, che consente al browser Web di comunicare con il server che contiene le pagine desiderate), altri protocolli dipendono dall’infrastruttura software di Internet; il tuo software non interagisce direttamente con loro, ma sono indispensabili.
Il protocollo, queste regole di comunicazione, sono indispensabili in una rete come Internet. Senza un protocollo, due programmi software semplicemente non potrebbero comunicare anche se i cavi sono collegati e le macchine sono accese. Senza protocollo, il software si troverebbe nella situazione di due umani, un francese che parla solo francese e un giapponese che parla solo giapponese. Anche se tutti e due hanno un telefono e conoscono il numero dell’altro, nessuna vera comunicazione potrà avvenire. L’intera Internet è basata sul concetto di protocollo.
Il protocollo consente l’interoperabilità. L’interoperabilità è la capacità di comunicare di due prodotti software diversi realizzati da team di sviluppo differenti. Se un’università boliviana può avere scambi con una società indiana, è perché entrambi usano protocolli comuni.

Un esempio classico di interoperabilita: la presa elettrica. Kae Kae [CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)%5D, via Wikimedia Commons
Solo i protocolli devono essere comuni: Internet non richiede l’uso dello stesso software né che il software abbia la stessa interfaccia con l’utente. Se prendo l’esempio di due software che parlano il protocollo HTTP, il browser Mozilla Firefox (che potresti usare per leggere questo articolo) e il programma curl (usato principalmente dagli informatici per le operazioni tecniche), questi due programmi hanno usi molto diversi, si interfacciano con l’utente in base a principi opposti, ma entrambi parlano lo stesso protocollo HTTP. Il protocollo è quello che parla con gli altri software (l’interfaccia con l’utente è invece per gli esseri umani.).
La distinzione tra protocollo e software è cruciale. Se uso il software A perché lo preferisco e tu il software B, finché i due programmi parlano lo stesso protocollo, nessun problema, sarà solo una scelta individuale. Nonostante le loro differenze, compresa l’interfaccia utente, entrambi i software comunicano. Se, d’altra parte, ogni software ha il proprio protocollo, non ci saranno comunicazioni, come nell’esempio fatto sopra del francese e e del giapponese.
Babele
Quindi, tutti i software utilizzano protocolli comuni, consentendo a tutti di comunicare felicemente? No, e non è obbligatorio. Internet è una rete con ”permesso opzionale “. A differenza dei vecchi tentativi di reti di computer che erano controllati dagli operatori telefonici e che decidevano quali protocolli e quali applicazioni avrebbero eseguito sulle loro reti, su Internet, puoi inventare il tuo protocollo, scrivere il software che lo parla e diffonderlo sperando di avere successo Questo è il modo in cui il Web è stato inventato: Tim Berners-Lee (e Robert Cailliau) non hanno dovuto chiedere il permesso a nessuno.Hanno definito il protocollo HTTP, scritto le applicazioni e la loro invenzione ha avuto successo.
Questa libertà di innovazione senza permesso è quindi una buona cosa. Ma ha anche degli svantaggi. Se ogni sviluppatore di applicazioni inventa il proprio protocollo, non ci saranno più comunicazioni o, più precisamente, non ci sarà più interoperabilità. Ogni utente sarà in grado di comunicare solo con persone che hanno scelto lo stesso software. Alcuni servizi su Internet hanno una buona interoperabilità, la posta elettronica, per esempio. Altri invece sono composti da un insieme di silos chiusi, che non comunicano tra loro. Questo è ad esempio il caso degli instant messenger. Ogni applicazione ha il proprio protocollo, le persone che usano WhatsApp non possono comunicare con chi usa Telegram, che non può comunicare con chi preferisce Signal o Riot. Mentre Internet è stata progettata per facilitare la comunicazione, questi silos, al contrario, bloccano i loro utenti in uno spazio chiuso.
La situazione è la stessa per i social network commerciali come Facebook. Puoi comunicare solo con persone che sono su Facebook. Le pratiche dell’azienda che gestisce questa rete sono deplorevoli, ad esempio nell’acquisizione e nell’utilizzo di dati personali, ma quando viene suggerito a chi usa Facebook di abbandonare questo silos, la risposta più comune è “ Non posso farlo, tutti i miei amici sono lì, e non potrei più comunicare con loro se me ne andassi . “Questo esempio è una buona illustrazione dei pericoli dei protocolli aziendali e, al contrario, dell’importanza dell’interoperabilità.
![Kae [CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons](https://nilocram.wordpress.com/wp-content/uploads/2019/06/1280px-pieter_bruegel_the_elder_-_the_tower_of_babel_vienna_-_google_art_project_-_edited.jpg)
La torre di babele, quadro di Pieter Bruegel il vecchio. Pubblico dominio,(Google Art Project)
Ma perché ci sono diversi protocolli per lo stesso servizio? Ci sono diversi motivi. Alcuni sono tecnici. Non li svilupperò qui, non è un articolo tecnico, ma i protocolli non sono tutti equivalenti, ci sono ragioni tecniche oggettive che possono fare scegliere un protocollo piuttosto che un altro. E poi due persone diverse potrebbero pensare che due servizi non sono realmente identici e quindi meritano protocolli separati, anche se tutti non sono d’accordo.
Ma possono esserci anche ragioni commerciali: l’azienda dominante non ha alcun desiderio che i giocatori più piccoli competano con essa e non vuole consentire l’ingresso di nuovi arrivati. Ha quindi una forte motivazione ad usare solo un suo protocollo, che nessun altro conosce.
Infine, ci possono essere anche ragioni più psicologiche, come la convinzione, nel creatore di un protocollo, che il suo protocollo sia molto migliore degli altri.
Un esempio di un recente successo in termini di adozione di un nuovo protocollo è dato dalla fediverse. Questo termine, contrazione di “federazione” e “universo” (in italiano fediverso) include tutti i server che comunicano tra di loro con il protocollo ActvityPub, che l’appello delle sessantanove organizzazioni cita come esempio. ActivityPub ti consente di scambiare un’ampia varietà di messaggi. I programmi Mastodon e Pleroma utilizzano ActivityPub per inviare brevi testi, che chiamiamo micro-blogging (come fa Twitter). PeerTube utilizza ActivityPub per vedere e commentare i nuovi video. WriteFreely fa lo stesso con i testi che questo software di blog consente di scrivere e distribuire. E, domani, Mobilizon utilizzerà ActivityPub per informazioni sugli eventi che permetterà di organizzare. Questo è un nuovo esempio della distinzione tra protocollo e software. Sebbene molte persone chiamino il fediverse “Mastodon “, questo è inesatto. Mastodon è solo uno dei software che consente l’accesso a fediverse.
Neanche il termine ActivityPub è l’ideale. Esiste infatti una serie di protocolli necessari per comunicare all’interno di fediverse. ActivityPub è solo uno di questi, ma ha dato il suo nome un po’ a tutto l’insieme.
Non tutti i software del movimento di “reti sociali decentralizzate” utilizzano ActivityPub. Ad esempio, Diaspora non lo usa e quindi non è interoperabile con gli altri.
Appello
Torniamo ora all’appello citato all’inizio. Che cosa chiede? Questo appello richiede che l’interoperabilità venga imposta ai GAFA, le grandi società capitaliste che si trovano in una posizione dominante nella comunicazione. Tutte sono silos chiusi. Non c’è modo di commentare un video di YouTube se si dispone di un account PeerTube, di seguire i messaggi su Twitter o Facebook se si è su fediverse. Queste GAFA non cambieranno spontaneamente: bisognerà costringerle.
Si tratta solo della comunicazione esterna. Questo appello è moderato, nel senso che non richiede alle GAFA di cambiare la loro interfaccia utente, la loro organizzazione interna, i loro algoritmi di selezione dei messaggi o le loro pratiche nella gestione dei dati personali. Si tratta solo di ottenere che esse consentano l’interoperabilità con i servizi concorrenti, in modo da consentire una reale libertà di scelta da parte degli utenti. Tale aggiunta è semplice da implementare per queste imprese commerciali, che hanno fondi abbondanti e un gran numero di programmatori competenti. E “aprirebbe” il campo delle possibilità. Si tratta quindi di difendere gli interessi degli utenti. (Mentre il governo, nei suoi commenti , ha citato solo gli interessi delle GAFA, come se fossero specie in pericolo che devono essere difese).
Chi comanda?
Ma chi decide i protocolli, chi li crea? Non c’è una risposta semplice a questa domanda. Esistono molti protocolli diversi e le loro origini sono varie. A volte sono scritti in un testo che descrive esattamente ciò che le due parti devono fare. Questo è chiamato una specifica. Ma a volte non c’è alcuna specifica, solo alcune idee vaghe e un programma che utilizza questo protocollo. Ad esempio, il protocollo BitTorrent, ampiamente utilizzato per lo scambio di file e per il quale esiste un’interoperabilità molto buona con molti software, non è stato oggetto di una specifica completa. Niente costringe gli sviluppatori: Internet è “a permesso opzionale “. In questi casi, chi volesse creare un programma interoperabile dovrà leggere il codice sorgente (le istruzioni scritte dal programmatore) o analizzare il traffico che circola, per cercare di dedurre quale sia il protocollo (quello che si chiama reverse engineering). Questo è ovviamente più lungo e più difficile ed è quindi molto auspicabile per l’interoperabilità che ci sia una specifica scritta e corretta (si tratta di un esercizio difficile, il che spiega perché alcuni protocolli non ce l’hanno).
A volte le specifiche sono formalmente adottate da un’organizzazione il cui ruolo è quello di sviluppare e approvare le specifiche. Questo si chiama standardizzazione. Una specifica approvata è uno standard. L’interesse di uno standard rispetto a una specifica ordinaria è che riflette, a priori, un consenso piuttosto ampio di una parte degli attori, non è più un atto unilaterale. Gli standard sono quindi una buona cosa, ma nulla è perfetto, quindi il loro sviluppo è a volte laborioso e lento.

Scrivere delle norme corrette e consensuali può essere laborioso. Codex Bodmer – Frater Rufillus (wohl tätig im Weißenauer Skriptorium) [Public domain]
Non tutti gli standard sono uguali. Alcuni sono disponibili pubblicamente (come importanti standard dell’infrastruttura Internet, RFC – richiesta di commenti), altri riservati a coloro che pagano o a quelli che sono membri di un club chiuso. Alcuni standard sono sviluppati pubblicamente, in cui tutti hanno accesso alle informazioni, altri sono creati dietro porte accuratamente chiuse. Quando lo standard è sviluppato da un’organizzazione aperta a tutti, secondo le procedure pubbliche, e il risultato è pubblicamente disponibile, si parla spesso di standard aperti. E, naturalmente, questi standard aperti sono preferibili per l’interoperabilità.
Una delle organizzazioni di standard aperti più conosciute è l’ Internet Engineering Task Force ( IETF), che produce la maggior parte delle RFC. L’IETF ha sviluppato e mantiene lo standard che descrive il protocollo HTTP, il primo citato in questo articolo. Ma esistono altre organizzazioni di standardizzazione, come il World Wide Web Consortium ( W3C ), che è responsabile per lo standard ActivityPub.
Ad esempio, per gli instant messenger che ho citato, esiste uno standard, che è chiamato Extensible Messaging and Presence Protocol (XMPP ). Google l’ha usato, poi l’ha abbandonato, giocando invece il gioco della chiusura.
Difficoltà
L’interoperabilità non è ovviamente una soluzione magica per tutti i problemi. Come abbiamo detto, l’appello delle sessantanove organizzazioni è molto moderato poiché richiede solo un’apertura a terzi. Se questa richiesta si traducesse in una legge che imponga questa interoperabilità, questo non risolverebbe tutto.
Innanzitutto, ci sono molti modi per rispettare la lettera di un protocollo, violando il suo spirito. Lo vediamo nella posta elettronica dove Gmail, in posizione dominante, impone regolarmente nuovi requisiti ai server di posta con i quali si degna di comunicare. L’email, a differenza della messaggistica istantanea, si basa su standard aperti, ma questi standard possono essere soddisfatti aggiungendo delle regole. Questo braccio di ferro mira a impedire ai server indipendenti di comunicare con Gmail. Se fosse adottata una legge che segue le raccomandazioni dell’appello, non c’è dubbio che le GAFA tenterebbero questo tipo di gioco e che dovrebbe esserci un meccanismo per monitorare l’applicazione della legge.
In modo più sottile, la società che volesse “aggirare” gli obblighi di interoperabilità può anche pretendere di voler “migliorare” il protocollo. Si aggiungono due o tre cose che non erano nello standard, e poi si fa pressione sulle altre organizzazioni perchè anche loro aggiungano quelle funzioni. Questo è un esercizio che i browser web hanno praticato molto, per ridurre la concorrenza.
Giocare con gli standard è tanto più facile in quanto alcuni standard sono scritti male, lasciando troppe ombre (e questo è il caso di ActivityPub). Scrivere uno standard è un esercizio difficile. Se lasciamo molta scelta ai programmatori che creeranno il software, c’è il rischio di distruggere l’interoperabilità, seguendo scelte troppo diverse. Ma se forziamo questi programmatori, imponendo regole molto precise per tutti i dettagli, impediamo al software di evolversi in risposta ai cambiamenti di Internet o del suo utilizzo. La standardizzazione rimane quindi un’arte difficile, per la quale non abbiamo un metodo perfetto.
Conclusione
Ecco, mi dispiace di essere stato lungo, ma i concetti di protocollo e interoperabilità sono poco insegnati, mentre sono cruciali per il funzionamento di Internet e soprattutto per la libertà dei cittadini che la usano . Spero di averli spiegati chiaramente e di averti convinto dell’importanza dell’interoperabilità. Pensa a sostenere l’appello delle sessantanove organizzazioni!
Per approfondire
E se vuoi maggiori informazioni su questo argomento:
-
Se preferisci l’audio al testo scritto, il podcast di APRIL ha parlato di interoperabilità.